-
Defended
And I finally defended my PhD thesis.

-
C3: Cutting Tail Latency in Cloud Data Stores via Adaptive Replica Selection
After a long hiatus of technical posts, I’m finally getting around to blogging about my PhD research. Today, I’ll give a brief overview of some of my recent work on the C3 system that was published at NSDI 2015.
My research has focused on techniques to reduce latency in the context of large-scale distributed storage systems. A common pattern in the way people architect scalable web-services today is to have large request fanouts, where even a single end-user request can trigger tens to thousands of data accesses to the storage tier. In the presence of such access patterns, the tail latency of your storage servers becomes very important since they begin to dominate the overall query time.
At the same time, storage servers are typically chaotic. Skewed demands across storage servers, queueing delays across various layers of the stack, background activities such as garbage collection and SSTable compaction, as well as resource contention with co-located workloads are some of the many factors that lead to performance fluctuations across storage servers. These sources of performance fluctuations can quickly inflate the tail-latency of your storage system, and degrade the performance of application services that depend on the storage tier.
In light of this issue, we investigate how replica selection, wherein a database client can select one out of multiple replicas to service a read request, can be used to cope with server-side performance fluctuations at the storage layer. That is, can clients carefully select replicas for serving reads with the objective of improving their response times?
This is challenging for several reasons. First of all, clients need a way to reliably measure and adapt to performance fluctuations across storage servers. Secondly, a fleet of clients needs to ensure that they do not enter herd behaviours or load oscillations because all of them are trying to improve their response times by going after faster servers. As it turns out, many popular systems either do a poor job of replica selection because they are agnostic to performance heterogeneity across storage servers, or are prone to herd behaviours because they get performance-aware replica selection wrong.
C3 addresses these problems through a careful combination of two mechanisms. First, clients in a C3 system, with some help from the servers, carefully rank replicas in order to balance request queues across servers in proportion to their performance differences. We refer to this as replica ranking. Second, C3 clients use a congestion-control-esque approach to distributed rate control, where clients adjust and throttle their sending rates to individual servers in a fully decentralized fashion. This ensures that C3 clients do not collectively send more requests per second to a server than it can actually process.
The combination of these two mechanisms gives C3 some impressive performance improvements over Cassandra’s Dynamic Snitching, which we used as a baseline. In experiments conducted on Amazon EC2, we found C3 to improve the 99.9th percentile latency by factors of 3x, while improving read throughput by up to 50%. See the paper for details regarding the various experiments we ran as well as the settings considered.
While the system evaluation in the paper was conducted using the Yahoo Cloud Serving Benchmark (YCSB), I’m currently investigating how C3 performs under production settings through some companies who’ve agreed to give it a test run. So far, the tests have been rather positive and we’ve been learning a lot more about C3 and the problem of replica selection in general. Stay tuned for more results!
-
Interactive Classroom Hack
I gave a lecture yesterday as part of a lab course I was TA-ing. The assignment for this week had to do with understanding how different TCP variants perform in a wireless setting.
To prepare students for the assignment, my lecture was designed to be a refresher on TCP’s basics.
My plan was to discuss what TCP sets out to accomplish, some of the early design problems associated with it, and how each subsequent improvement of TCP solved a problem that the previous one didn’t (or introduced). This could have been a very one-sided lecture, with me parroting all of the above. But the best way to keep a classroom interactive is to deliver a lecture packed with questions, and have the students come up with the answers.
This meant that I began the lecture by asking students what TCP tries to accomplish. The students threw all kinds of answers at me, and we discussed each of them one after the other. We talked about what reliability means, how reliable TCP’s guarantee of reliability actually is, and from a performance standpoint, what TCP tries to accomplish. Note, at this point I’m still on slide number 1 with only “What are TCP’s objectives?” on it. Next, we went into the law of conservation of packets, and I asked them why that matters. After that round of discussions were complete, we started with TCP Tahoe. I posed each problem that TCP Tahoe tries to fix, the problems it doesn’t fix, and also asked them what the ramification is/would be of a certain design decision of Tahoe. This went on for a while, with the students getting more and more worked up about the topic, until we finally covered all the TCP variants I had planned on teaching. By this point, the students themselves had discussed, debated and attempted to solve each of the many issues associated with making TCP perform well.
Next, we moved on to the problems associated with TCP over wireless, and I asked them to suggest avenues for constructing a solution. The discussion that followed was pretty exciting, and at some point they even began correcting and arguing with each other. Little did they know, that this one line problem statement I offered them took several PhD theses to even construct partially working solutions.
I’ve tried different variations of this strategy in the past, and after all these years I’ve concluded this: Leaving students with questions during a lecture puts them in the shoes of those before them who tried to find the answers. Leaving students with the answers makes them mere consumers of knowledge.
When we tell students about a solution alongside the problem itself, we’ve already put horse blinders on their chain of thought. We’re directing their thoughts through a linear chain. Leaving them with the questions long enough enough makes them think more, and in my opinion, works very well in making a classroom interactive.
-
Academic Abandonware
I recently stumbled upon this.
The gist of the discussion is that a good deal of CS research published at reputable venues is notoriously difficult or even impossible to replicate. Hats off to the team from Arizona for helping to bring this to the limelight. It’s something we as a community ought to be really concerned about.
Among the most common reasons seem to be:
- None of the authors can be contacted for any help relating to the paper.
- Single points of failure: the only author capable of reproducing the work has graduated.
- The objective of publishing a paper being accomplished, the software went unmaintained and requires divine intervention to even build/setup, let alone use.
- The software used or built in the paper cannot be publicly released. This is either due to licensing reasons, the first two points, or plain refusal by the authors.
- Critical details that are required to re-implement the work are omitted from the paper.
One of the criticisms I have with the study is that their methodology involved marking a piece of code as “cannot build” if 30 minutes of programmer time was insufficient to build the tool. I doubt many of my own sincere attempts to make code publicly available would pass this test. Odin comes to my mind here, which is a pain to setup despite the fact that others have and do successfully use it for their research.
So what can we do to minimise academic abandonware? Packaging your entire software environment into VMs and releasing them via a project website sounds to me like an idea worth pursuing. It avoids the problem of having to find, compile and link combinations of ancient libraries. True, it doesn’t help if one requires special hardware resources or a testbed in order to run the system, but it’s a start nevertheless. Investing time and research into building thoroughly validated simulators and emulators may also aid in this direction.
I’ll end this post with a comic I once drew.
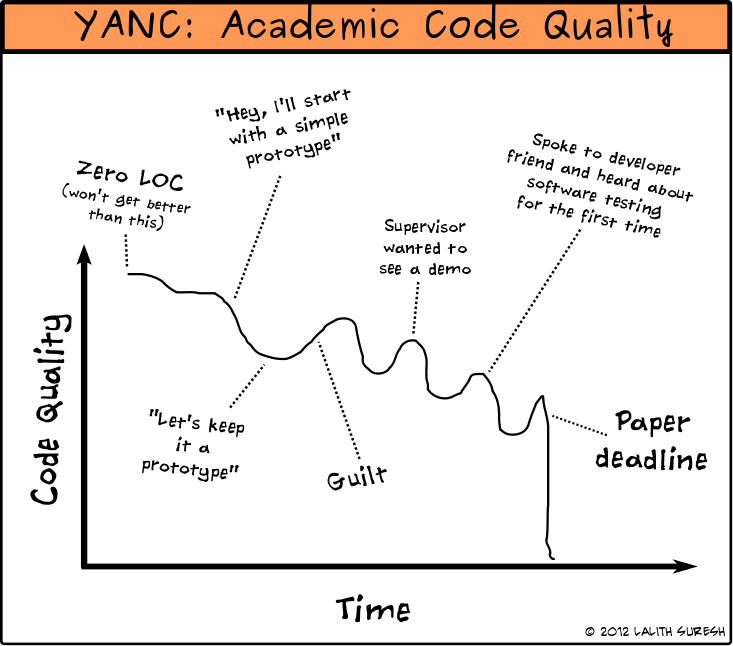
-
Mental Detox
I’ve had a couple of paper deadlines in the last few months, all of which were not-so-conveniently placed a couple of hours apart from each other. While the month leading up to it was insanely stressful, I managed to push out most of what I had in the pipeline and don’t have any more paper deadlines to worry about for a few months.
I’m now doing the usual post-submission-mental-detox to clear up my head, where I’ve been taking it easy at work and catching up on life in general. I’ve been completing some pending reviews, preparing an undergraduate course for the upcoming semester, and rabidly catching up on lost gaming time. I’m also going on holiday to Argentina in a week, an opportunity to completely disconnect from work all together.
This freedom to manage my time the way that suits me best is what I enjoy the most about doing a PhD. I can be working insanely hard in the weeks leading up to a deadline to push out a paper, and then slow down for a while to to clear up again.
Now back to exploring dungeons in Skyrim.