Academic Abandonware
I recently stumbled upon this.
The gist of the discussion is that a good deal of CS research published at reputable venues is notoriously difficult or even impossible to replicate. Hats off to the team from Arizona for helping to bring this to the limelight. It’s something we as a community ought to be really concerned about.
Among the most common reasons seem to be:
- None of the authors can be contacted for any help relating to the paper.
- Single points of failure: the only author capable of reproducing the work has graduated.
- The objective of publishing a paper being accomplished, the software went unmaintained and requires divine intervention to even build/setup, let alone use.
- The software used or built in the paper cannot be publicly released. This is either due to licensing reasons, the first two points, or plain refusal by the authors.
- Critical details that are required to re-implement the work are omitted from the paper.
One of the criticisms I have with the study is that their methodology involved marking a piece of code as “cannot build” if 30 minutes of programmer time was insufficient to build the tool. I doubt many of my own sincere attempts to make code publicly available would pass this test. Odin comes to my mind here, which is a pain to setup despite the fact that others have and do successfully use it for their research.
So what can we do to minimise academic abandonware? Packaging your entire software environment into VMs and releasing them via a project website sounds to me like an idea worth pursuing. It avoids the problem of having to find, compile and link combinations of ancient libraries. True, it doesn’t help if one requires special hardware resources or a testbed in order to run the system, but it’s a start nevertheless. Investing time and research into building thoroughly validated simulators and emulators may also aid in this direction.
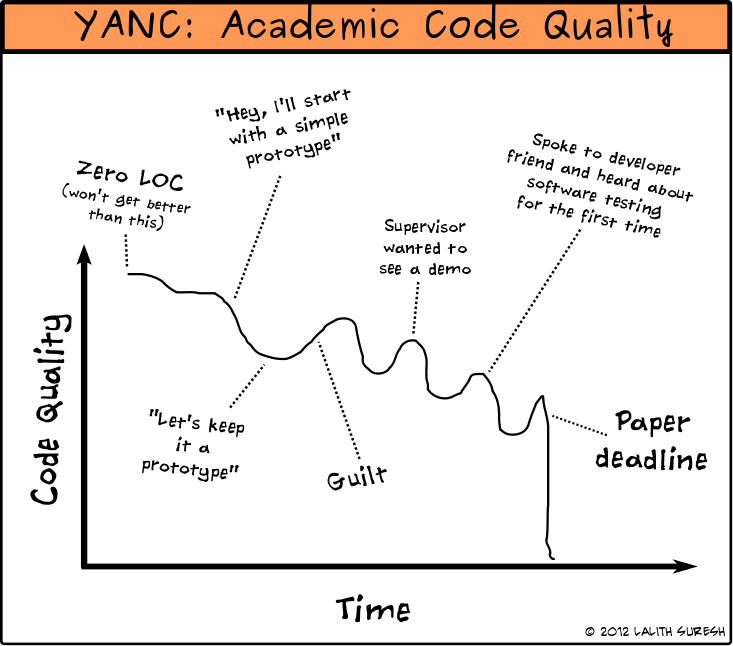
I’ll end this post with a comic I once drew.
Comments