Rapid: Stable and Consistent Membership at Scale
This post gives an overview of our recent work on the Rapid system, presented at USENIX ATC 2018 (you can find the paper, slides and presentation audio here ).
Rapid is a scalable, distributed membership service – it allows processes to form clusters and receive notifications when the membership changes.
Why design another membership service?
Rapid is motivated by two key challenges.
First, we observe that datacenter failure scenarios are not always crash failures, but commonly involve misconfigured firewalls, one-way connectivity loss, flip-flops in reachability, and some-but-not-all packets being dropped. However, existing membership solutions struggle with these common failure scenarios, despite being able to cleanly detect crash faults. In particular, existing tools take long to, or never converge to, a stable state where the faulty processes are removed. This is problematic in any distributed system: membership changes often trigger failure recovery workflows, and repeatedly triggering these workflows can not only degrade system performance, but also cause widespread outages.
Second, we note that inconsistent membership views in a system pose a challenging programming abstraction for developers, especially for building critical features in a distributed system like failure recovery. Without strong consistency semantics, developers need to write code where a process can make no assumptions about the world view of the rest of the system.
Enter Rapid
Rapid is a scalable, distributed membership system that is stable in the face of a diverse range of failure scenarios, and provides participating processes a strongly consistent view of the system’s membership. In particular, Rapid guarantees that all processes see the same sequence of membership changes to the system.
Rapid drives membership changes through three steps: maintaining a monitoring overlay, identifying a membership change proposal from monitoring alerts, and arriving at agreement among processes on a proposal. In each of these steps, we make design decisions that contribute to our goals of stability and consistency.
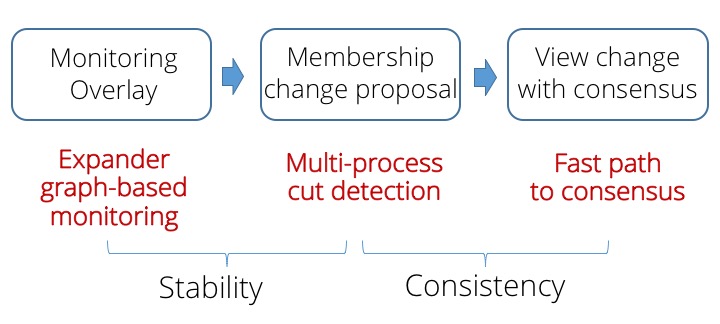
Expander-based monitoring edge overlay. Rapid organizes a set of processes (a configuration) into a stable failure detection topology comprising observers that monitor and disseminate reports about their communication edges to their subjects. The monitoring relationships between processes forms a directed expander graph with strong connectivity properties, which ensures with a high probability that healthy processes detect failures. We interpret multiple reports about a subject’s edges as a high-fidelity signal that the subject is faulty. The monitoring edges represent edge failure detectors that are pluggable.
Multi-process cut detection. For stability, processes in Rapid (i) suspect a faulty process p only upon receiving alerts from multiple observers of p, and (ii) delay acting on alerts about different processes until the churn stabilizes, thereby converging to detect a global, possibly multi-node cut of processes to add or remove from the membership. This filter is remarkably simple to implement, yet it suffices by itself to achieve almost-everywhere agreement – unanimity among a large fraction of processes about the detected cut.
Practical consensus. For consistency, we show that converting almost-everywhere agreement into full agreement is practical even in large-scale settings. Rapid’s consensus protocol drives configuration changes by a low-overhead, leaderless protocol in the common case: every process simply validates consensus by counting the number of identical cut detections. If there is a quorum containing three-quarters of the membership set with the same cut, then without a leader or further communication, this is a safe consensus decision.
How well does it work?
We experimented with Rapid in moderately scalable settings comprising 1000-2000 nodes.
The paper has detailed head-to-head comparisons against widely used membership solutions, like Akka Cluster, ZooKeeper and Memberlist. The higher-order bit is that these solutions deal well with crash failures and network parititions, but face stability issues under complex network failure scenarios like asymmetric reachability issues and high-packet loss. Rapid is stable under these circumstances because of its expander-based monitoring overlay that can better localize faults and its approach of removing entire cuts of faulty processes.
At the same time, Rapid is also fast. It can bootstrap a 2000 node cluster 2-5.8x faster than the alternatives we compared against, despite the fact that Rapid offers much stronger guarantees around stability and consistency.
Lastly, Rapid is comparable in cost to Memberlist (a gossip-based protocol) in terms of network bandwidth and memory utilization.
We also found Rapid easy to integrate in two existing applications: a distributed transaction data-store, and a service discovery use case.
We believe the insights we identify in Rapid are easy to apply to existing systems, and are happy to work with you on your use case. Feel free to reach out to me if you’d like to chat!
References
USENIX ATC 2018 paper, slides and
presentation
Code on Github
VMware Research
Group
Comments